Another busy week in fedora infrastructure. Here's my attempt at a recap
of the more interesting items.
Inscrutable vHMC
We have a vHMC vm. This is a virtual Hardware Management Console for our power10 servers.
You need one of these to do anything reasonably complex on the servers.
I had initially set it up on one of our virthosts just as a qemu raw image,
since thats the way the appliance is shipped. But that was making the root
filesystem on that server be close to full, so I moved it to a logical volume
like all our other vm's. However, after I did that, it started getting high
packet loss talking to the servers. Nothing at all should have changed network
wise, and indeed, it was the only thing seeing this problem. The virthost,
all the other vm's on it, they were all fine. I rebooted it a bunch, tried
changing things with no luck.
Then, we had our mass update/reboot outage thursday. After rebooting that virthost,
everything was back to normal with the vHMC. Very strange. I hate problems
that just go away where you don't know what actually caused them, but
at least for now the vHMC is back to normal.
Mass update/reboot cycle
We did a mass update/reboot cycle this last week. We wanted to:
Update all the RHEL9 instances to 9.7 which just came out
Update all the RHEL10 instances to 10.1 which just came out.
Update all the fedora builders from f42 to f43
Update all our proxies from f42 to f43
Update a few other fedora instances from f42 to f43
This overall went pretty smoothly and everything should be updated and working now.
Please do file an issue if you see anything amiss (as always).
AI Scrapers / DDoSers
The new anubis is working I think quite well to keep the ai scrapers at bay now.
It is causing some problems for some clients however. It's more likely to find
a client that has no user-agent or accept header might be a bot. So, if you are
running some client that hits our infra and are seeing anubis challenges, you should
adjust your client to send a user-agent and accept header and see if that
gets you working again.
The last thing we are seeing thats still anoying is something I thought
was ai scraping, but now I am not sure the motivation of it, but here's what
I am seeing:
LOTS of requests from a large amount of ip's
fetching the same files
all under forks/$someuser/$popularpackage/ (so forks/kevin/kernel or the like)
passing anubis challenges
My guess is that these may be some browser add on/botnet where they don't care
about the challenge, but why fetch the same commit 400 times? Why hit the same
forked project for millions of hits over 8 or so hours?
If this is a scraper, it's a very unfit one, gathering the same content
over and over and never moving on. Perhaps it's just broken and looping?
In any case currently the fix seems to be just to block requests to
those forks, but of course that means the user who's fork it is cannot
access them. ;( Will try and come up with a better solution.
RDU2-CC to RDU3 move
This datacenter move is still planned to happen. :)
I was waiting for a new machine to migrate things to, but it's stuck in
process, so instead I just repurposed for now a older server that
we still had around. I've setup a new stg.pagure.io on it and copied
all the staging data to it, it seems to be working as expected, but
I haven't moved it in dns yet.
I then setup a new pagure.io there and am copying data to it now.
The current plan if all goes well is to have an outage and move
pagure.io over on december 3rd.
Then, on December 8th, the rest of our RDU2-CC hardware will
be powered off and moved. The rest of the items we have there
shouldn't be very impactful to users and contributors. download-cc-rdu01
will be down, but we have a bunch of other download servers.
Some proxies will be down, but we have a bunch of other proxy servers.
After stuff comes back up on the 8th or 9th we will bring
things back on line.
US Thanksgiving
Next week is the US Thanksgiving holiday (on thursday). We get
thursday and friday as holidays at Red Hat, and I am taking
the rest of the week off too. So, I might be around some in
community spaces, but will not be attending any meetings or
doing things I don't want to.
RC5 was GOLD, so version 8.5.0 GA was just released, at the planned date.
A great thanks to Volker Dusch, Daniel Scherzer and Pierrick Charron, our Release Managers, to all developers who have contributed to this new, long-awaited version of PHP, and to all testers of the RC versions who have allowed us to deliver a good-quality version.
RPMs are available in the php:remi-8.5 module for Fedora and Enterprise Linux ≥ 8 and as Software Collection in the remi-safe repository.
For memory, this is the result of 6 months of work for me to provide these packages, starting in July for Software Collections of alpha versions, in September for module streams of RC versions, and also a lot of work on extensions to provide a mostly full PHP 8.5 stack.
This is a report created by CLE Team, which is a team containing community members working in various Fedora groups for example Infratructure, Release Engineering, Quality etc. This team is also moving forward some initiatives inside Fedora project.
Week: 17 November – 21 November 2025
Fedora Infrastructure
This team is taking care of day to day business regarding Fedora Infrastructure. It’s responsible for services running in Fedora infrastructure. Ticket tracker
The intermittent 503 timeout issues plaguing the infra appear to finally be resolved, kudos to Kevin and the Networking team for tracking it down.
The Power10 hosts which caused the outage last week are now installed and ready for use.
Crashlooping OCP worker caused issues with log01 disk space
Monitoring migration to Zabbix is moving along, with discussions of when to make it “official”.
AI scrapers continue to cause significant load. A change has been made to bring some of the hits to src.fpo under the Varnish cache, which may help.
This team is taking care of day to day business regarding CentOS Infrastructure and CentOS Stream Infrastructure. It’s responsible for services running in CentOS Infratrusture and CentOS Stream. CentOS ticket tracker CentOS Stream ticket tracker
https://cbs.centos.org is now fully live from RDU3 (DC-move) : kojihub/builders in rdu3 and/or remote AWS VPC isolated network, and also signing/releng process
Release Engineering
This team is taking care of day to day business regarding Fedora releases. It’s responsible for releases, retirement process of packages and package builds. Ticket tracker
F43 RISC-V rebuild status: the delta for F43 RISC-V is still about ~2.5K packages compared to F43 primary. Current plan: once we hit ~2K package delta, we’ll start focusing on the quality of the rebuild and fix whatever important stuff that needs fixing. (Here is the last interim update to the community.)
Community highlight: David Abdurachmanov (Rivos Inc) has been doing excellent work on Fedora 43 rebuild, doing a lot of heavy-lifting. He also provides quite some personal hardware for Koji rebuilders.
If you’re wearing more than one hat on your head something is probably wrong. In open source, this can feel like running a haberdashery, with a focus on juggling roles and responsibilities that sometimes conflict, instead of contributing. In October, I attended the first OpenSSL Conference and got to see some amazing talks and, more importantly, meet some truly wonderful people and catch up with friends.
Disclaimer: I work at Microsoft on upstream Linux in Azure and was formerly at Red Hat. These reflections draw on roles I’ve held in various communities and at various companies. These are personal observations and opinions.
Let’s start by defining a hat. This is a situation where you are in a formalized role, often charged with representing a specific perspective, team, or entity. The formalization is critical. There is a difference between a contributor saying something, even one who is active in many areas of the project, and the founder, a maintainer, or the project leader saying it. That said, you are always you, regardless of whether you have one hat, a million hats, or none. You can’t be a jerk in a forum and then expect everyone to ignore that when you show up at a conference. Hats don’t change who you are.
During a few of the panels, several panelists were trying to represent multiple points of view. They participate or have participated in multiple ways, for example on behalf of an employer and out of personal interest. One speaker has a collection of colored berets they take with them onto the stage. Over the course of their comments they change the hat on their head to talk to different, and quite often all, sides of a question. I want to be clear, I am not calling this person out. This is the situation they feel like they are in.
I empathize with them because I have been in this same situation. I have participated in the Fedora community as an individually motivated contributor, the Fedora Community Action and Impact Coordinator (a paid role provided to the community by Red Hat), and as the representative of Red Hat discussing what Red Hat thinks. Thankfully, I never did them all at once, just two at a time. I felt like I was walking a tightrope. Stressful. I didn’t want my personal opinion to be taken as the “voice” of the project or of Red Hat.
This experience was formative and helped me navigate this the next time it came up when I became Red Hat’s representative to the CentOS Project Board. My predecessor in the role had been a long-time individual contributor and was serving as the Red Hat representative. They struggled with the hats game. The first thing I was told was that the hat switching was tough to follow and people were often unsure if they were hearing “the voice of Red Hat” or the “voice of the person.” I resolved to not further this. I made the decision that I would only ever speak as “the voice of Red Hat.”1 It would be clear and unambiguous.
But, you may be thinking, what if you, bex, really have something you personally want to say. It did happen and what I did was leverage the power of patience and friendship.
Patience was in the form of waiting to see how a conversation developed. I am very rarely the smartest person in the room. I often found that someone would propose the exact thing I was thinking of, sometimes even better or more nuanced than I would have.
On the rare occasions that didn’t happen I would backchannel one of my friends in the room and ask them to consider saying what I thought. The act of asking was useful for two reasons. One, it was a filter for things that may not have been useful to begin with. Two, if someone was uneasy with sharing my views, their feedback was often useful in helping me better understand the situation.
In the worst case, if I didn’t agree with their feedback, I could ask someone else. Alternatively, I could step back and examine what was motivating me so strongly. Usually that reflection revealed this was a matter of personal preference or style that wouldn’t affect the outcome in the long term. It was always possible that I’d hit an edge case where I genuinely needed a second hat.
I recognize this is not an easy choice to make. I had the privilege of not having to give up an existing role to make this decision. However, I believe that in most cases when you do have to give up one role for another, you’re better off not trying to play both parts. You’re likely blocking or impeding the person who took on the role you gave up. If you have advice a quiet sidebar with them will go further than potentially forcing them into public conversations that don’t need to be public. Your successor may do things differently, you should be ok with that. And remember what I wrote above, you’re not being silenced.
So when do multiple hats tend to happen? Here are some common causes of hat wearing:
When you’re in a project because your company wants you there and you are personally interested in the technology.
You participate in the project and a fork, downstream, or upstream that it has a relationship with.
You participate in multiple projects all solving the same problem, for example multiple Linux distributions.
You sit on a standards body or other organization that has general purview over an area and are working on the implementation.
You work on both an open source project and the product it is commercially sold as.
You’re a member of a legally liable profession, such as a lawyer (in many jurisdictions) so anything you say can be held to that standard.
You’re in a small project and because of bootstrapping (or community apathy) you’re filling multiple roles during a “forming” phase.
This raises the question of which hat you should wear if you feel like you have more than one option. Here’s how I decide which hat to wear:
Is this really a multi-hat situation? Are you just conflicted because you have views as a member of multiple projects or as someone who contributes in multiple ways that aren’t in alignment? If it isn’t a formalized role you’re struggling with the right problem. Speak your mind. Share the conflict and lack of alignment. This is the meat of the conversation.
Why are you here? You generally know. That is the hat you wear. If you’re at a Technical Advisory Committee Meeting on behalf of your company and an issue about which you are personally passionate comes up - remember patience and friendship because this is a company hat moment.
If you are in a situation where you can truly firewall off the conversations, you can change to an alternative hat. What this means is when you find yourself in a space where the provider of your other hat is very uninvolved. For example, if you normally work on crypto for your employer, but right now you are making documentation website CSS updates. Hello personal hat.
If you’re in a 1:1 conversation and you know the person well, you can lay out all of your thoughts - just avoid the hat language. Be direct and open. If you don’t know the person well, you should probably err on the side of being conservative and think carefully about states 1 and 2 above.
Some will argue that in smaller projects or early-stage efforts the flexibility of multiple roles is a feature, not a bug, allowing for rapid adaptation before formal structures are needed. That’s fair during a “forming” phase - but it shouldn’t become permanent. As the project matures, work to clarify roles and expectations so contributors can focus on one hat at a time.
As a maintainer or project leader, when you find people wearing multiple hats, it’s a warning flag. Something isn’t going right. Figure it out before the complexity becomes unmanageable.
In the case of this role it meant I spent a lot of time not saying much as Red Hat didn’t have opinions on many community issues preferring to see the community make its own decisions. Honestly, I probably spent more time explaining why I wasn’t talking than actually talking. ↩
RPMs of PHP version 8.4.15 are available in the remi-modular repository for Fedora ≥ 41 and Enterprise Linux ≥ 8 (RHEL, Alma, CentOS, Rocky...).
RPMs of PHP version 8.3.28 are available in the remi-modular repository for Fedora ≥ 41 and Enterprise Linux ≥ 8 (RHEL, Alma, CentOS, Rocky...).
ℹ️ The packages are available for x86_64 and aarch64.
ℹ️ There is no security fix this month, so no update for versions 8.1.33 and 8.2.29.
These versions are also available as Software Collections in the remi-safe repository.
⚠️ These versions introduce a regression in MySQL connection when using an IPv6 address enclosed in square brackets. See the report #20528. A fix is under review and will be released soon.
As FPL I believe Fedora needs to be part of a healthy flatpak ecosystem. I’d like to share my journey in working towards that over the last few months with you all, and include some of the insights that I’ve gained. I hope by sharing this with you it will encourage those who share my belief to join with me in the journey to take us to a better future for Fedora and the entire ecosystem.
The immediate goal
First, my immediate goal is to get the Fedora ChangeProposal that was submitted to make Flathub the default remote for some of the Atomic desktops accepted on reproposal. I believe implementing the idea expressed in that ChangeProposal is the best available option for the Atomic desktops that help us down the path I want to see us walking together.
There seems to be wide appeal from both the maintainers of specific Fedora outputs, and the subset of Fedora users of those desktop outputs, that using Flathub is the best tradeoff available for the defaults. I am explicitly not in favor of shuttering the Fedora flatpaks, but I do see value in changing the default remote, where it is reasonable and desirable to do so. I continue to be sensitive to the idea that Fedora Flatpaks can exist because it is delivering value to a subset of users, even when it’s not the default remote but still targeting an overlapping set of applications serving different use cases. I don’t view this as a zero-sum situation; the important discussion right now is about what the defaults should be for specific Fedora outputs.
What I did this summer
There is a history of change proposals being tabled and then coming back in the next cycle after some of the technical concerns were addressed. There is nothing precedent-setting in how the Fedora Engineering Steering Committee handled this situation. Part of getting to the immediate goal, from my point of view, was doing the due diligence on some of the concerns raised in the FESCo discussion leading to the decision to table the proposal in the last release. So in an effort to get things in shape for a successful outcome for the reproposal, I took it on myself to do some of the work to understand the technical concerns around the corresponding source requirements of the GPL and LGPL licenses.
I felt like we were making some good progress in the Fedora discussion forums back in July. In particular, Timothee was a great help and wrote up an entirely new document on how to get corresponding sources for applications built in flathub’s infrastructure. That discussion and the resulting documentation output showed great progress in bringing the signal to noise ratio up and addressing the concerns raised in the FESCo discussion. In fact, this was a critical part of the talk I gave at GUADEC. People came up to me after that talk and said they weren’t aware of that extension that Timothee documented. We were making some really great progress out in the open and setting a stage for a successful reproposal in the next Fedora cycle.
Okay, that’s all context intended to help you, dear reader, understand where my head is at. Hopefully we can all agree my efforts were aligned with the goal leading up to late July. The next part gets a bit harder to talk about, and involves a discussion of communication fumbles, which is not a fun topic.
The last 3 months
Unfortunately, at GUADEC I found a different problem, one I wasn’t expecting to find. Luckily, I was able to communicate face to face with people involved and they confirmed my findings, committed on the spot to get it fixed, and we had a discussion on how to proceed. This started an embargo period where I couldn’t participate in the public narrative work in the community I lead. That embargo ended up being nearly 3 months. I don’t think any of us who spoke in person that day at GUADEC had any expectation that the embargo would last so long.
Through all of this, I was in communication with Rob McQueen, VP of the Gnome Foundation, and one of the Flathub founders, checking in periodically on when it was reasonable for me to start talking publicly again. It seems that the people involved in resolving the issues took it so seriously that they not only addressed the deficiencies I found -missing files- but committed to creating significant tooling changes to help prevent it from happening again. Some characterized that work as “busting their asses.” That’s great, especially considering much of that work is probably volunteer effort. Taking the initiative to solve not just the immediate problem, but building tooling to help prevent it is a fantastic commitment, and in line with what I would expect from the volunteers in the Fedora community itself. We’re more aligned than we realize I think.
What I’ve learned from this is there’s a balance with regard to embargos that must be struck. Thinking about it, we might have been better served if we had agreed to scope the embargo at the outset and then adjusted later with a discussion on extending the time further, that also gave me visibility into why it was taking additional time. It’s one of the ideas I’d like to talk to people about to help ensure this is handled better in the future. There are opportunities to do the sensitive communications a bit better in the future, and I hope in the weeks ahead to talk with people about some ideas on that.
Now with the embargo lifted, I’ve resumed working towards a successful change reproposal. I’ve restarted my investigation of corresponding source availability for the runtimes. We lost 3 months to the embargo, but I think there is still work to be done. Already, in the past couple of weeks, I’ve had one face to face discussion with a FESCo member, specifically about putting a reproposal together, and got useful feedback on the approach to that.
So that’s where we are at now. What’s next?
The future
I am still working on understanding how source availability works for the Flathub runtimes. I think there is a documentation gap here, like there was for the flatpak-builder sources extension. My ask to the Fedora community, particularly those motivated to find paths forward for Flathub as the default choice for bootc based Fedora desktops, is to join me in clarifying how source availability for the critical FLOSS runtimes works so we can help Flathub by contributing documentation that all Flathub users can find and make use of.
Like I said in my GUADEC talk, having a coherent (but not perfect) understanding of how Fedora users can get the flatpak corresponding sources and make local patched builds is important to me to figure out as we walk towards a future where Flathub is the default remote for Fedora. We have to get to a future where application developers can look at the entire linux ecosystem as one target. I think this is part of what takes the Linux desktop to the next level. But we need to do it in a way that ensures that end users have access to all the necessary source code to stay in control of their FLOSS software consumption. Ensuring users have the ability to patch and build software for themselves is vital, even if it’s never something the vast majority of users will need to do. Hopefully, we’re just a couple more documents away from telling that story adequately for Flathub flatpaks.
I’ve found that some of the most contentious discussions can be with people with whom you actually have a significant amount of agreement. Back in graduate school, when my officemate and I would talk about anything we both felt well-informed about and were in high agreement on: politics, comic books, science, whatever it was.. we’d get into some of the craziest, heated arguments about our small differences of opinion, which were minor in comparison to how much we agreed on. And it was never about needing to be right at the expense of the other person. It was never about him proving me wrong or me proving him wrong. It was because we really deeply wanted to be even more closely aligned. After all, we valued each other’s opinions. It’s weird to think about how much energy we spent doing that. And I get some of the same feeling that this is what’s going on now around flatpaks. Sometimes we just need to take a second and value the alignment we do have. I think there’s a lot to value right now in the Fedora and Flathub relationship, and I’m committed to find ways both communities can add value to each other as we walk into the future.
A few weeks ago, Daniel Stenberg highlighted that the curl project had — for a moment, at least — zero open issues in the GitHub tracker. (As of this writing, there are three open issues.) How can a project that runs on basically everything even remotely resembling a computer achieve this? The project has written some basics, and I’ve poked around to piece together a generalizable approach.
But first: why?
Is “zero issues” a reasonable goal? Opinions differ. There’s no One Right Way to manage an issue tracker. No matter how you choose to do it, someone will be mad about it. In general projects should handle issues however they want, so long as the expectations are clearly managed. If everyone involved knows what to expect (ideally with documentation), that’s all that matters.
In Producing Open Source Software, Karl Fogel wrote “an accessible bug database is one of the strongest signs that a project should be taken seriously — and the higher the number of bugs in the database, the better the project looks.” But Fogel does not say “open bugs”, nor do I think he intended to. A high number of closed bugs is probably even better than a high-ish number of open bugs.
I have argued for closing stale issues (see: Your Bug Tracker and You) on the grounds that it sends a clear signal of intent. Not everyone buys into that philosophy. To keep the number low, as the project seems to consistently do, curl has to take an approach that heavily favors closing issues quickly. Their apparent approach is more aggressive than I’d personally choose, but it works for them. If you want it to work for you, here’s how.
Achieving zero issues
If you want to reach zero issues (or at least approach it) for your project, here are some basic principles to follow.
Focus the issue tracker. curl’s issue tracker is not for questions, conversations, or wishing. Because curl uses GitHub, these vaguer interactions can happen on the repo’s built-in discussion forum. And, of course, curl has a mailing list for discussion, too.
Close issues when the reporter is unresponsive. As curl’s documentation states: “nobody responding to follow-up questions or questions asking for clarifications or for discussing possible ways to move forward [is] a strong suggestion that the bug is unimportant.” If the reporter hasn’t given you the information you need to diagnose and resolve the issue, then what are you supposed to do about it?
Document known bugs. If you’ve confirmed a bug, but no one is immediately planning to fix it, then add it to a list of known bugs. curl does this and then closes the issue. If someone decides they want to fix a particular bug, they can re-open the issue (or not).
Maintain a to-do list. You probably have more ideas than time to implement them. A to-do list will help you keep those ideas ready for anyone (including Future You) that wants to find something to work on. curl explicitly does not track these in the issue tracker and uses a web page instead.
Close invalid or unreproducible issues. If a bug can’t be reproduced, it can’t be reliably fixed. Similarly, if the bug is in an upstream library or downstream distribution that your project can do nothing about, there’s no point in keeping the issue open.
Be prepared for upset people; document accordingly. Not everyone will like your issue management practices. That’s okay. But make sure you’ve written them down so that people will know what to expect (some, of course, will not read it). As a bonus, as you grow your core contributors, everyone will have a reference for managing issues in a consistent way.
These packages are weak dependencies of Redis, so they are installed by default (if install_weak_deps is not disabled in the dnf configuration).
The modules are automatically loaded after installation and service (re)start.
The modules are not available for Enterprise Linux 8.
3. Future
Valkey also provides a similar set of modules, requiring some packaging changes already proposed for Fedora official repository.
Redis may be proposed for unretirement and be back in the Fedora official repository, by me if I find enough motivation and energy, or by someone else.
I may also try to solve packaging issues for other modules (e.g. RediSearch). For now, module packages are very far from Packaging Guidelines, so obviously not ready for a review.
Release Candidate versions are available in the testing repository for Fedora and Enterprise Linux (RHEL / CentOS / Alma / Rocky and other clones) to allow more people to test them. They are available as Software Collections, for parallel installation, the perfect solution for such tests, and as base packages.
RPMs of PHP version 8.4.15RC1 are available
as base packages in the remi-modular-test for Fedora 41-43 and Enterprise Linux≥ 8
as SCL in remi-test repository
RPMs of PHP version 8.3.28RC1 are available
as base packages in the remi-modular-test for Fedora 41-43 and Enterprise Linux≥ 8
as SCL in remi-test repository
ℹ️ The packages are available for x86_64 and aarch64.
ℹ️ PHP version 8.2 is now in security mode only, so no more RC will be released.
Well, it's been a few weeks since I made one of these recap blog posts.
Last weekend I was recovering from some oral surgery, the weekend before
I had been on PTO on friday and was trying to be 'away'.
Lots of things happened in the last few weeks thought!
tcp timeout issue finally solved!
As contributors no doubt know we have been fighting a super anoying tcp
timeout issue. Basically just sometimes requests from our proxies to
backend services just timeout. I don't know how many hours I spent on
this issue trying everything I could think of, coming up with theorys
and then disproving them. Debugging was difficult because _most_ of the
time everything worked as expected. Finally, after a good deal of pain
I was able to get a tcpdump showing that when it happens the sending side
sends a SYN and the receiving side sees nothing at all.
This all pointed to the firewall cluster in our datacenter.
We don't manage that, our networking folks do. It took some prep work,
but last week they were finally able to update the firmware/os in
the cluster to the latest recommended version.
After that: The problem was gone!
I don't suppose we will ever know the exact bug that was happening here,
but one final thing to note: When they did the upgrade the cluster had
over 1 million active connections. After the upgrade it has about 150k.
So, seems likely that it was somehow not freeing resources correctly
and dropping packets or something along those lines.
I know this problem has been anoying to contributors.
It's personally been very anoying to me, my mind kept focusing on it
and not anything else. It kept me awake at night. ;(
In any case finally solved!
There is a new outstanding issue that has occurred from the upgrade:
https://pagure.io/fedora-infrastructure/issue/12913
basically long running koji cli watch tasks ( watch-task / watch-logs)
are getting a 502 error after a while. This does not affect the
task in any way, just the watching of it. Hopefully we can
get to the bottom of this and fix it soon.
outages outages outages
We have had a number of outages of late. They have been for different
reasons, but it does make it frustrating trying to contribute.
A recap of a few of them:
AI scrapers continue to mess with us. Even though most of our services
are behind anubis now, they find ways around that, like fetching css or
js files in loops, hitting things that are not behind anubis and
generally making life sad. We continue to block things as we can.
The impact here is mostly that src.fedoraproject.org is sensitive to
high load and we need to make sure and block things before it impacts commits.
We had two outages ( friday 2025-11-07 and later monday 2025-11-10 )
That were caused by a switch loop when I brought up a power10 lpar.
This was due to the somewhat weird setup on the power10 lpars where they
shouldn't be using the untagged/native vlan at all, but a build vlan.
The friday outage took a while for us to figure out what was causing it.
The monday outage was very short. All those lpars are correctly configured
now and up and operating ok.
We had a outage on monday ( 2025-11-10 ) where a set of crashlooping
pods filled up our log server with tracebacks and generally messed with
everything. Pod was fixed, storage was cleared up.
We had some kojipkgs outages on thursday ( 2025-11-13 ) and friday
( 2025-11-14 ). These were caused by many requests for directory listings for
some ostree objects directories. Those directories have ~65k files in
them each, so apache has to stat 64k files each time it gets those requests.
But then, cloudfront (which is making the request) times out after 30s
and resends. So, you get a load average of 1000 and very slow processing.
So, for now we put that behind varnish, so it just has to do it the first
time for a dir and then it can send the cached result to all the rest.
If that doesn't fix it, we can look at just disabling indexes there,
but I am not sure the implications.
We had a nice discussion in the last fedora infrastructure meeting about
tracking outages better and trying to do a RCA on them after the fact
to make sure we solved it or at least tried to make it less likely to
happen again.
I am really hoping for some non outage days and smooth sailing for a bit.
power10s
I think we are finally done with the power10 setup. Many thanks again to
Fabian on figuring out all the bizare and odd things we needed to do to
configure the servers as close to the way we want them as possible.
The fedora builder lpars are all up and operating since last week.
The buildvm-ppc64les on them should have more memory and cpus that before
and hopefully are faster for everyone. We have staging lpars also now.
The only final thing to do is to get the coreos builders installed.
The lpars themselves are all setup and ready to go.
rdu2-cc to rdu3 datacenter move
I haven't really been able to think about this due to outages and timeout
issue, but things will start heating up next week again.
It seems unlikely that we will get our new machine in time to matter now,
so I am moving to a new plan: repurposing another server there to
migrate things to. I plan to try and get it setup next week and sync
pagure.io data to a new pagure instance there. Depending on how that looks
we might move to it first week of december.
Theres so much more going on, but those are some highlights I recall...
This is a weekly report from the I&R (Infrastructure & Release Engineering) Team. We provide you both infographic and text version of the weekly report. If you just want to quickly look at what we did, just look at the infographic. If you are interested in more in depth details look below the infographic.
Week: 10th – 14th November 2025
Infrastructure & Release Engineering
The purpose of this team is to take care of day to day business regarding CentOS and Fedora Infrastructure and Fedora release engineering work. It’s responsible for services running in Fedora and CentOS infrastructure and preparing things for the new Fedora release (mirrors, mass branching, new namespaces etc.). List of planned/in-progress issues
We did it again, Fedora at Kirinyaga university in Kenya. This time, we didn’t just introduce what open source is – we showed students how to participate and actually contribute in real time.
Many students had heard of open source before, but were not sure how to get started or where they could fit. We did it hands-on and began with a simple explanation of what open source is: people around the world working together to create tools, share knowledge, and support each other. Fedora is one of these communities. It is open, friendly, and built by different people with different skills.
We talked about the many ways someone can contribute, even without deep technical experience. Documentation, writing guides, design work, translation, testing software, and helping new contributors are all important roles in Fedora. Students learned that open source is not only for “experts.” It is also for learners. It is a place to grow.
Hands-on Documentation Workshop
After the introduction, we moved into a hands-on workshop. We opened Fedora Docs and explored how documentation is structured. Students learned how to find issues, read contribution instructions, and make changes step-by-step. We walked together through:
Opening or choosing an issue to work on
Editing documentation files
Making a pull request (PR)
Writing a clear contribution message
By the end of the workshop, students had created actual contributions that went to the Fedora project. This moment was important. It showed them that contributing is not something you wait to do “someday.” You can do it today.
Through the guidance of Cornelius Emase, I was able to make my first pull request to the Fedora Project Docs – my first ever contribution to the open-source world. ” – Student at Kirinyaga University
Thank you note
Huge appreciation to:
Jona Azizaj — for steady guidance and mentorship.
Mat H. — for backing the vision of regional community building.
Fedora Mindshare Team — for supporting community growth here in Kenya.
Computer Society of Kirinyaga — for hosting and bringing real energy into the room.
And to everyone who played a part – even if your name isn’t listed here, I see you. You made this possible.
Growing the next generation
The students showed interest, curiosity, and energy. Many asked how they can continue contributing and how to connect with the wider Fedora community. I guided them to Fedora Docs, Matrix community chat rooms, and how they can be part of the Fedora local meetups here in Kenya.
We are introducing open source step-by-step in Kenya. There is a new generation of students who want to be part of global technology work. They want to learn, collaborate, and build. Our role is to open the door and walk together(I have a discourse post on this, you’re welcome to add your views).
What Comes Next
This event is part of a growing movement to strengthen Fedora’s presence in Kenya. More events will follow so that learning and contributing can continue.
We believe that open source becomes strong when more people are included. Fedora is a place where students in Kenya can learn, grow, share, and contribute to something global.
We already had a Discourse thread running for this event – from the first announcement, planning, and budget proposal, all the way to the final workshop. Everything happened in the open. Students who attended have already shared reflections there, and anyone who wants to keep contributing or stay connected can join the conversation.
You can check the events photos submitted here on Google photos(sorry that’s not FOSS:))
Cornelius Emase, Your Friend in Open Source(Open Source Freedom Fighter)
When we launched Vhsky.cz a year ago, we did it to provide an alternative to the near-monopoly of YouTube. I believe video distribution is so important today that it’s a skill we should maintain ourselves.
To be honest, it’s bothered me for the past few years that even open-source conferences simply rely on YouTube for streaming talks, without attempting to secure a more open path. We are a community of tech enthusiasts who tinker with everything and take pride in managing things ourselves, yet we just dump our videos onto YouTube, even when we have the tools to handle it internally. Meanwhile, it’s common for conferences abroad to manage this themselves. Just look at FOSDEM or Chaos Communication Congress.
This is why, from the moment Vhsky.cz launched, my ambition was to broadcast talks from OpenAlt—a conference I care about and help organize. The first small step was uploading videos from previous years. Throughout the year, we experimented with streaming from OpenAlt meetups. We found that it worked, but a single stream isn’t quite the stress test needed to prove we could handle broadcasting an entire conference.
For several years, Michal Vašíček has been in charge of recording at OpenAlt, and he has managed to create a system where he handles recording from all rooms almost single-handedly (with assistance from session chairs in each room). All credit to him, because other conferences with a similar scope of recordings have entire teams for this. However, I don’t have insight into this part of the process, so I won’t focus on it. Michal’s job was to get the streams to our server; our job was to get them to the viewers.
OpenAlt’s AV background with running streams. Author: Michal Stanke.
Stress Test
We only got to a real stress test the weekend before the conference, when Bashy prepared a setup with seven streams at 1440p resolution. This was exactly what awaited us at OpenAlt. Vhsky.cz runs on a fairly powerful server with a 32-core i9-13900 processor and 96 GB of RAM. However, it’s not entirely dedicated to PeerTube. It has to share the server with other OSCloud services (OSCloud is a community hosting of open source web services).
We hadn’t been limited by performance until then, but seven 1440p streams were truly at the edge of the server’s capabilities, and streams occasionally dropped. In reality, this meant 14 continuous transcoding processes, as we were streaming in both 1440p and 480p. Even if you don’t change the resolution, you still need to transcode the video to leverage useful distribution features, which I’ll cover later. The 480p resolution was intended for mobile devices and slow connections.
Remote Runner
We knew the Vhsky.cz server alone couldn’t handle it. Fortunately, PeerTube allows for the use of “remote runners”. The PeerTube instance sends video to these runners for transcoding, while the main instance focuses only on distributing tasks, storage, and video distribution to users. However, it’s not possible to do some tasks locally and offload others. If you switch transcoding to remote runners, they must handle all the transcoding. Therefore, we had to find enough performance somewhere to cover everything.
I reached out to several hosting providers known to be friendly to open-source activities. Adam Štrauch from Roští.cz replied almost immediately, saying they had a backup machine that they had filed a warranty claim for over the summer and hadn’t tested under load yet. I wrote back that if they wanted to see how it behaved under load, now was a great opportunity. And so we made a deal.
It was a truly powerful machine: a 48-core Ryzen with 1 TB of RAM. Nothing else was running on it, so we could use all its performance for video transcoding. After installing the runner on it, we passed the stress test. As it turned out, the server with the runner still had a large reserve. For a moment, I toyed with the idea of adding another resolution to transcode the videos into, but then I decided we’d better not tempt fate. The stress test showed us we could keep up with transcoding, but not how it would behave with all the viewers. The performance reserve could come in handy.
Load on the runner server during the stress test. Author: Adam Štrauch.
Smart Video Distribution
Once we solved the transcoding performance, it was time to look at how PeerTube would handle video distribution. Vhsky.cz has a bandwidth of 1 Gbps, which isn’t much for such a service. If we served everyone the 1440p stream, we could serve a maximum of 100 viewers. Fortunately, another excellent PeerTube feature helps with this: support for P2P sharing using HLS and WebRTC.
Thanks to this, every viewer (unless they are on a mobile device and data) also becomes a peer and shares the stream with others. The more viewers watch the stream, the more they share the video among themselves, and the server load doesn’t grow at the same rate.
A two-year-old stress test conducted by the PeerTube developers themselves gave us some idea of what Vhsky could handle. They created a farm of 1,000 browsers, simulating 1,000 viewers watching the same stream or VOD. Even though they used a relatively low-performance server (quad-core i7-8700 CPU @ 3.20GHz, slow hard drive, 4 GB RAM, 1 Gbps connection), they managed to serve 1,000 viewers, primarily thanks to data sharing between them. For VOD, this saved up to 98% of the server’s bandwidth; for a live stream, it was 75%:
If we achieved a similar ratio, then even after subtracting 200 Mbps for overhead (running other services, receiving streams, data exchange with the runner), we could serve over 300 viewers at 1440p and multiples of that at 480p. Considering that OpenAlt had about 160 online viewers in total last year, this was a more than sufficient reserve.
Live Operation
On Saturday, Michal fired up the streams and started sending video to Vhsky.cz via RTMP. And it worked. The streams ran smoothly and without stuttering. In the end, we had a maximum of tens of online viewers at any one time this year, which posed no problem from a distribution perspective.
In practice, the server data download savings were large even with just 5 peers on a single stream and resolution.
Our solution, which PeerTube allowed us to flexibly assemble from servers in different data centers, has one disadvantage: it creates some latency. In our case, however, this meant the stream on Vhsky.cz was about 5-10 seconds behind the stream on YouTube, which I don’t think is a problem. After all, we’re not broadcasting a sports event.
Diagram of the streaming solution for OpenAlt. Labels in Czech, but quite self-explanatory.
Minor Problems
We did, however, run into minor problems and gained experience that one can only get through practice. During Saturday, for example, we found that the stream would occasionally drop from 1440p to 480p, even though the throughput should have been sufficient. This was because the player felt that the delivery of stream chunks was delayed and preemptively switched to a lower resolution. Setting a higher cache increased the stream delay slightly, but it significantly reduced the switching to the lower resolution.
Subjectively, even 480p wasn’t a problem. Most of the screen was taken up by the red frame with the OpenAlt logo and the slides. The speaker was only in a small window. The reduced resolution only caused slight blurring of the text on the slides, which I wouldn’t even have noticed as a problem if I wasn’t focusing on it. I could imagine streaming only in 480p if necessary. But it’s clear that expectations regarding resolution are different today, so we stream in 1440p when we can.
Over the whole weekend, the stream from one room dropped for about two talks. For some rooms, viewers complained that the stream was too quiet, but that was an input problem. This issue was later fixed in the recordings.
When uploading the talks as VOD (Video on Demand), we ran into the fact that PeerTube itself doesn’t support bulk uploads. However, tools exist for this, and we’d like to use them next time to make uploading faster and more convenient. Some videos also uploaded with the wrong orientation, which was likely a problem in their metadata, as PeerTube wasn’t the only player that displayed them that way. YouTube, however, managed to handle it. Re-encoding them solved the problem.
On Saturday, to save performance, we also tried transcoding the first finished talk videos on the external runner. For these, a bar is displayed with a message that the video failed to save to external storage, even though it is clearly stored in object storage. In the end we had to reupload them because they were available to watch, but not indexed.
A small interlude – my talk about PeerTube at this year’s OpenAlt. Streamed, of course, via PeerTube:
Thanks and Support
I think that for our very first time doing this, it turned out very well, and I’m glad we showed that the community can stream such a conference using its own resources. I would like to thank everyone who participated. From Michal, who managed to capture footage in seven lecture rooms at once, to Bashy, who helped us with the stress test, to Archos and Schmaker, who did the work on the Vhsky side, and Adam Štrauch, who lent us the machine for the external runner.
If you like what we do and appreciate that someone is making OpenAlt streams and talks available on an open platform without ads and tracking, we would be grateful if you supported us with a contribution to one of OSCloud’s accounts, under which Vhsky.cz runs. PeerTube is a great tool that allows us to operate such a service without having Google’s infrastructure, but it doesn’t run for free either.
This period is open until Wednesday, 2025-11-26 at 23:59:59 UTC.
Candidates may self-nominate. If you nominate someone else, check with them first to ensure that they are willing to be nominated before submitting their name.
Nominees do not yet need to complete an interview. However, interviews are mandatory for all nominees. Nominees not having their interview ready by end of the Interview period (2025-12-03) will be disqualified and removed from the election. Nominees will submit questionnaire answers via a private Pagure issue after the nomination period closes on Wednesday, 2025-11-26. The F43 Election Wrangler (Justin Wheeler) will publish the interviews to the Community Blog before the start of the voting period on Friday, 2025-12-05.
The elected seats on FESCo are for a two-release term (approximately twelve months). For more information about FESCo, please visit the FESCo docs.
The full schedule of the elections is available on the Elections schedule. For more information about the elections, process see the Elections docs.
My house has a handful of Amazon Echo Dot devices that we mostly use for timers, turning lights on and off, and playing music. They work well and have been an easy solution. I also use Home Assistant for some basic home automation and serve most everything I want to verbally control to the Echo Dots from Home Assistant.
I don’t use the Nabu Casa Home Assistant Cloud Service. If you’re reading this and you want the easy route, consider it — the cloud service is convenient. One benefit of the service is that there is a UI toggle to mark which entities/devices to expose to voice assistants.
If you take the manual route, like I do, you must set up a developer account, AWS Lambda, and maintain a hand-coded list of entity IDs in a YAML file.
Fun, right? Maintaining that list is tedious. I generally don’t mess with my Home Assistant installation very often. Therefore, when I need to change what is exposed to Alexa or add a new device, finding the actual entity_id is annoying. This is not helped by how good Home Assistant has gotten at showing only friendly names in most places. I decided there had to be a better way to do this other than manually maintaining YAML.
After some digging through docs and the source, I found there isn’t a built-in way to build this list by labels, categories, or friendly names. The Alexa integration supports only explicit entity IDs or glob includes/excludes.
So I worked out a way to build the list with a Home Assistant automation. It isn’t fully automatic - there’s no trigger that runs right before Home Assistant reboots - and you still need to restart Home Assistant when the list changes. But it lets me maintain the list by labeling entities rather than hand-editing YAML.
After a few experiments and some (occasionally overly imaginative) AI help, I arrived at this process. There are two parts.
Prep and staging
In your configuration.yaml enable the Alexa Smart Home Skill to use an external list of entity IDs. I store mine in /config/alexa_entities.yaml.
Place this script in scripts.yaml. It does three things:
Clears the existing file.
Finds all entities labeled with the tag you choose (I use “Alexa”).
Appends each entity ID to the file.
export_alexa_entities:alias:Export Entities with Alexa Labelsequence:# 1. Clear the file-service:shell_command.clear_alexa_entities_file# 2. Loop through each entity and append-repeat:for_each:"{{label_entities('Alexa')}}"sequence:-service:shell_command.append_alexa_entitydata:entity:"{{repeat.item}}"mode:single
Why clear the file and write it line by line? I couldn’t get any file or notify integration to write to /config, and passing a YAML list to a shell command collapses whitespace into a single line. Reformatting that back into proper YAML without invoking Python was painful, so I chose to truncate and append line-by-line. It’s ugly, but it’s simple and it works.
The result is that I can label entities in the UI and avoid tedious bookkeeping.
Last week in Rijeka we held Science festival 2015. This is the (hopefully not unlucky) 13th instance of the festival that started in 2003. Popular science events were organized in 18 cities in Croatia.
I was invited to give a popular lecture at the University departments open day, which is a part of the festival. This is the second time in a row that I got invited to give popular lecture at the open day. In 2014 I talked about The Perfect Storm in information technology caused by the fall of economy during 2008-2012 Great Recession and the simultaneous rise of low-cost, high-value open-source solutions. Open source completely changed the landscape of information technology in just a few years.
In 2012 University of Rijeka became NVIDIAGPU Education Center (back then it was called CUDA Teaching Center). For non-techies: NVIDIA is a company producing graphical processors (GPUs), the computer chips that draw 3D graphics in games and the effects in modern movies. In the last couple of years, NVIDIA and other manufacturers allowed the usage of GPUs for general computations, so one can use them to do really fast multiplication of large matrices, finding paths in graphs, and other mathematical operations.
Viewpoints are not detailed reviews of the topic, but instead, present the author's view on the state-of-the-art of a particular field.
The first of two articles stands for open source and open data. The article describes Quantum Chemical Program Exchange (QCPE), which was used in the 1980s and 1990s for the exchange of quantum chemistry codes between researchers and is roughly equivalent to the modern-day GitHub. The second of two articles questions the open-source software development practice, advocating the usage and development of proprietary software. I will dissect and counter some of the key points from the second article below.
But there is a story from the workshop which somehow remained untold, and I wanted to tell it at some point. One of the attendants, Valérie Vaissier, told me how she used proprietary quantum chemistry software during her Ph.D.; if I recall correctly, it was Gaussian. Eventually, she decided to learn CP2K and made the switch. She liked CP2K better than the proprietary software package because it is available free of charge, the reported bugs get fixed quicker, and the group of developers behind it is very enthusiastic about their work and open to outsiders who want to join the development.
Over the last few years, AMD has slowly been walking the path towards having fully opensourcedrivers on Linux. AMD did not walk alone, they got help from RedHat, SUSE, and probably others. Phoronix also mentions PathScale, but I have been told on Freenode channel #radeon this is not the case and found no trace of their involvement.
AMD finally publically unveiled the GPUOpen initiative on the 15th of December 2015. The story was covered on AnandTech, Maximum PC, Ars Technica, Softpedia, and others. For the open-source community that follows the development of Linux graphics and computing stack, this announcement comes as hardly surprising: Alex Deucher and Jammy Zhou presented plans regarding amdgpu on XDC2015 in September 2015. Regardless, public announcement in mainstream media proves that AMD is serious about GPUOpen.
I believe GPUOpen is the best chance we will get in this decade to open up the driver and software stacks in the graphics and computing industry. I will outline the reasons for my optimism below. As for the history behind open-source drivers for ATi/AMD GPUs, I suggest the well-written reminiscence on Phoronix.
Even though the open sourcing of a bunch of their software is a very nice move from Microsoft, I am still not convinced that they have changed to the core. I am sure there are parts of the company who believe that free and open source is the way to go, but it still looks like a change just on the periphery.
All the projects they have open-sourced so far are not the core of their business. Their latest version of Windows is no more friendly to alternative operating systems than any version of Windows before it, and one could argue it is even less friendly due to more Secure Boot restrictions. Using Office still basically requires you to use Microsoft's formats and, in turn, accept their vendor lock-in.
Put simply, I think all the projects Microsoft has opened up so far are a nice start, but they still have a long way to go to gain respect from the open-source community. What follows are three steps Microsoft could take in that direction.
In June 2014, Elon Musk opened up all Tesla patents. In a blog post announcing this, he wrote that patents "serve merely to stifle progress, entrench the positions of giant corporations and enrich those in the legal profession, rather than the actual inventors." In other words, he joined those who believe that free knowledge is the prerequisite for a great society -- that it is the vibrancy of the educated masses that can make us capable of handling the strange problems our world is made of.
The movements that promote and cultivate this vibrancy are probably most frequently associated with terms "Open access" and "open source". In order to learn more about them, we Q&A-ed VedranMiletić, the Rocker of Science -- researcher, developer and teacher, currently working in computational chemistry, and a free and open source software contributor and activist. You can read more of his thoughts on free software and related themes on his great blog, NudgedElasticBand. We hope you will join him, us, and Elon Musk in promoting free knowledge, cooperation and education.
Today I vaguely remembered there was one occasion in 2006 or 2007 when some guy from the academia doing something with Java and Unicode posted on some mailing list related to the free and open-source software about a tool he was developing. What made it interesting was that the tool was open source, and he filed a patent on the algorithm.
Hobbyists, activists, geeks, designers, engineers, etc have always tinkered with technologies for their purposes (in early personal computing, for example). And social activists have long advocated the power of giving tools to people. An open hardware movement driven by these restless innovators is creating ingenious versions of all sorts of technologies, and freely sharing the know-how through the Internet and more recently through social media. Open-source software and more recently hardware is also encroaching upon centers of manufacturing and can empower serious business opportunities and projects.
The free software movement is cited as both an inspiration and a model for open hardware. Free software practices have transformed our culture by making it easier for people to become involved in producing things from magazines to music, movies to games, communities to services. With advances in digital fabrication making it easier to manipulate materials, some now anticipate an analogous opening up of manufacturing to mass participation.
You seem to be using Sphinx for your teaching materials, right? As far as I can see, it doesn't have an online WYSIWYG editor. I would be interested in comparison of your solution with e.g. MediaWiki.
While the advantages and the disadvantages of static site generators, when compared to content management systems, have been written about and discussed already, I will outline our reasons for the choice of Sphinx below. Many of the points have probably already been presented elsewhere.
The last day of July happened to be the day that Domagoj Margan, a former student teaching assistant and a great friend of mine, set up his own DigitalOceandroplet running a web server and serving his professional website on his own domain domargan.net. For a few years, I was helping him by providing space on the server I owned and maintained, and I was always glad to do so. Let me explain why.
A mirror is a local copy of a website that's used to speed up access for the users residing in the area geographically close to it and reduce the load on the original website. Content distribution networks (CDNs), which are a newer concept and perhaps more familiar to younger readers, serve the same purpose, but do it in a way that's transparent to the user; when using a mirror, the user will see explicitly which mirror is being used because the domain will be different from the original website, while, in case of CDNs, the domain will remain the same, and the DNS resolution (which is invisible to the user) will select a different server.
Free and open-source software was distributed via (FTP) mirrors, usually residing in the universities, basically since its inception. The story of Linux mentions a directory on ftp.funet.fi (FUNET is the Finnish University and Research Network) where Linus Torvalds uploaded the sources, which was soon after mirrored by Ted Ts'o on MIT's FTP server. The GNU Project's history contains an analogous process of making local copies of the software for faster downloading, which was especially important in the times of pre-broadband Internet, and it continues today.
Back in summer 2017. I wrote an article explaining why we used Sphinx and reStructuredText to produce teaching materials and not a wiki. In addition to recommending Sphinx as the solution to use, it was general praise for generating static HTML files from Markdown or reStructuredText.
This summer I made the conversion of teaching materials from reStructuredText to Markdown. Unfortunately, the automated conversion using Pandoc didn't quite produce the result I wanted so I ended up cooking my own Python script that converted the specific dialect of reStructuredText that was used for writing the contents of the group website and fixing a myriad of inconsistencies in the writing style that accumulated over the years.
Tough question, and the one that has been asked and answeredoverandover. The simplest answer is, of course, it depends on many factors.
As I started blogging at the end of my journey as a doctoral student, the topic of how I selected the field and ultimately decided to enroll in the postgraduate studies never really came up. In the following paragraphs, I will give a personal perspective on my Ph.D. endeavor. Just like other perspectives from doctors of not that kind, it is specific to the person in the situation, but parts of it might apply more broadly.
This month we had Alumni Meeting 2023 at the Heidelberg Institute for Theoretical Studies, or HITS for short. I was very glad to attend this whole-day event and reconnect with my former colleagues as well as researcherscurrentlyworking in the area of computational biochemistry at HITS. After all, this is the place and the institution where I worked for more than half of my time as a postdoc, where I started regularly contributing code to GROMACS molecular dynamics simulator, and published some of my best papers.
My employment as a research and teaching assistant at Faculty of Informatics and Digital Technologies (FIDIT for short), University of Rijeka (UniRi) ended last month with the expiration of the time-limited contract I had. This moment has marked almost two full years I spent in this institution and I think this is a good time to take a look back at everything that happened during that time. Inspired by therecentposts by the PI of my group, I decided to write my perspective on the time that I hope is just the beginning of my academic career.
Recently, I listened to a talk by someone I highly respect in the FOSS world, Brian “bex” Exelbierd, at OpenAlt. In his talk “Bring Wood for the Fire”, bex describes how communities come together around the fire to discuss and collaborate about ideas and share different perspectives.
The campfire is used as a metaphor for a gathering or conference of an open source community, as a place where everyone can contribute to keeping the fire alive. Between speakers, organizers, and the attendees in the hallway tracks, those conversations give life to the event and bring everyone around the fire.
From time to time, you might want to re-initialize rpmautospec
in your RPM package’s (Dist)Git repo (rpmautospec is the tool that expands
%autorelease and %autochangelog templates in specfiles).
The motivations for this step might be simple:
the tool is analyzing an excessively long Git history
you are attempting to handle shallow Git clones
you want to migrate the package from one DistGit to another (e.g., from Fedora
to CentOS Stream)
TL;DR: we need to prevent rpmautospec logic from analyzing beyond the last
two Git commits. The tool behaves this way only when the very last commit (a)
modifies the Version: and (b) changes the changelog file (the file with
expanded %changelog).
This implies we need to make two precisely formatted commits.
Step-by-step guide
(Re)generate the changelog file (do not ‘git add’ the file for now; this
change belongs in the second commit):
rpmautospec generate-changelog > changelog
TODO: if we move from rpm to norpm, we need to use the full RPM
parser one last time here; document how.
Set a placeholder version, e.g., Version: 0.
Do not worry; no builds are performed for the first commit. You might want
to apply other changes here as well, such as dropping %lua macros from the
Epoch if present.
Remove the %autochangelog and %autorelease templates from the spec file.
To keep things simple, you can just set Release: 0.
Make the first commit (spec file changes only, keep the changelog
file changes uncommitted!).
Set the Version: field appropriately (think of Turing-Complete macros).
Reintroduce the %autochangelog and %autorelease templates.
Make the second commit. Include the changelog change. The Version
reset we did means that the calculated %autorelease is re-started from
Release: 1—if you need a different value, say 5, add the string
[bump release: 5] into the commit message.
Optional step: You might want to add one more empty commit using
git commit --allow-empty to bump the Release and generate %changelog
entry. (This depends on your distribution’s policy.)
We have ongoing intermittent issues with the communication between the Fedora
proxies and the backend services. This manifests as intermittent 502 / 503
errors when talking to services such as Koji, Src, and so on.
We are working with the networking team to track it down, see the Pagure ticket
for …
I spend more time than I care to admit staring at computer screens. It’s an occupational hazard, literally, of writing about tech for a living.
Much of that time is spent staring into the abyss a text editor, in this case Emacs. That being the case, I have test-driven quite a few different fonts to find one that is:
Pleasant to look at and isn’t boring.
Easy to read.
Displays code nicely.
Makes it easy to distinguish characters like l and 1.
I ran across Avería recently and it immediately caught my eye. It is, according to its web site, “the average of all fonts” on the creator’s computer. Somehow, at least to my aging eyes, it looks simultaneously classic and modern.
Many services at our main datacenter are down/unresponsive.
There seems to be a networking event going on.
We are working with networking to track down and mitigate things.
Updates as they become available.
This is a weekly report from the I&R (Infrastructure & Release Engineering) Team. We provide you with both an infographic and a text version of the weekly report. If you just want to quickly look at what we did, just look at the infographic. If you are interested in more in-depth details, look below the infographic.
Week: 03rd – 07th November 2025
Infrastructure & Release Engineering
The purpose of this team is to take care of day-to-day business regarding CentOS and Fedora Infrastructure and Fedora release engineering work. It’s responsible for services running in Fedora and CentOS infrastructure and preparing things for the new Fedora release (mirrors, mass branching, new namespaces, etc.). List of planned/in-progress issues
The Fedora community is coming together once again to celebrate the release of Fedora Linux 43, and you’re invited! Join us on Friday, November 21, 2025, from 13:00 to 16:00 UTC on Matrix for our virtual Fedora 43 Release Party.
This is our chance to celebrate the latest release, hear from contributors across the project, and see what’s new in Fedora Workstation, KDE, Atomic Desktops, and more. Whether you’re a long-time Fedora user or new to the community, it’s the perfect way to connect with the broader community, learn more about Fedora, and hang out in Matrix chat with your Fedora friends.
We have a lineup of talks and updates from across the Fedora ecosystem, including updates directly from teams who have been working on changes in this release. We’ll kick things off with Fedora Project Leader Jef Spaleta and Fedora Community Architect Justin Wheeler, followed by sessions with community members like Timothée Ravier on Atomic Desktops, Peter Boy and Petr Bokoč on the new Fedora Docs initiative, and Neal Gompa and Michel Lind discussing the Wayland-only GNOME experience. You’ll also hear from teams across Fedora sharing insights, demos, and what’s next for the project.
Registration is free but required to join the Matrix event room. Once registered, you’ll receive an invitation in your Matrix account before the event begins.
A while back, Emily Omier posted on LinkedIn about what she called “transactional” open source, that is to say, giving contribution gifts. Emily was against it. “The magic of open source,” she wrote, “is that it’s not purely transactional.” Turning contributions to transactional relationships changes the nature of the community. I understand her argument, but I think the answer is more nuanced.
The rewards of gifts
There’s nothing inherently wrong with transactional open source. Not every project or contributor wants to work that way, but when they both do, go for it! Everyone has different motivations, so it’s important to recognize and reward contributors in a way that is meaningful to them.
Some people may participate solely to earn a t-shirt. That’s okay. They still made a contribution they wouldn’t have otherwise. Your project benefits from that.
Plus, getting people in the door is the first step in converting them into long-term contributors. A lot of people who come just for a gift won’t stick around, but some will. And gifts can lead to more contributions from the existing contributor base, too.
The risks of gifts
Gifts are often (relatively) expensive and logistically-challenging. The money you spend acquiring and shipping gifts is money that your project can’t spend on things with a better return, like test hardware. Plus, it can take a long time to get the gift into the hands of the recipient. I’ve had packages to India take close to a year to reach their destination. With tariff changes, if you’re shipping into the US from the rest of the world, your contributor may be on the hook for import fees.
If you order ahead to get volume discounts, you have to store the stuff somewhere. And, of course, you have to know how you’re going to decide who gets the gifts. As I wrote in chapter 4 of Program Management for Open Source Projects: “figuring out an equitable way to distribute [1,000 t-shirts] is hard, but it’s a good problem to have. It’s still a problem to solve, though.”
For company-backed projects, there’s a risk of using transaction-avoidance as an excuse to be extractive. The argument could go something like this: “we want to be good open source participants, so we won’t tarnish the purity of these volunteer contributions by spending our money to give people gifts.” The real motivation is to keep the money.
Planning to give contribution gifts
If you’ve decided that you want to give gifts for contributions, you have to start with a plan. The first thing to understand is “why?” Everything else flows from the answer to that question. What behavior are you trying to encourage? Will the gift you offer induce that behavior? Who will handle the gifts?
You have to know what action or actions will trigger a gift. Is it the first contribution? Every contribution? Contributions to specific under-developed areas (like documentation or tests)? Personal or project milestones?
Next, what gifts will you give? It’s important to recognize and reward contributors in a way that is meaningful to them and encourages a sense of belonging. For some people, simple recognition in release notes or a blog post is enough. Some might love a great pair of socks, while others have no more room in their drawer. The environmental impact of cheap thumb drives, USB cables, and t-shirts will harm your reputation with some people. There’s no universal answer.
Then there’s the question of who will take the time to collect information, distribute gifts, and handle follow-up questions. If a gift doesn’t ship for months (or does ship, but takes a long time to be delivered), you’ll undoubtedly have people asking about it. Time spent handling this work is time not spent elsewhere.
If you choose to give contribution gifts, it needs to be part of a broader recognition and incentive program. In general, I suggest saving physical gifts for established contributors, but be very liberal with shout outs and digital badges.
A few minutes ago I was answering an email in Thunderbird, and I realized one thing that might have been there for years. The date was in the wrong format! (Wrong as in for me, of course).
I use English (US) for my desktop environment, but I change the format of several things because I don’t use the metric system, and I need the Euro sign and normal dates. Sorry, but month, day, and year is a weird format.
The “normal” thing would be to use my country format. But if I select a format from Spain, I get dates in Spanish and in a format that I also hate:
Yes, we have many different languages in Spain.
What I want is ISO8601 and English. But I don’t want to modify each field manually. Too much. The weird trick is to use Denmark (English). I am not kidding. And I am not alone. At all.
Weird, huh?
Why, you may ask? Look at this beauty. It’s just perfect.
Thank you, Denmark
Anyway. My problem is with Thunderbird. It looks like it doesn’t support having a language and a format from different regions. Thankfully they documented it here.
So now, I have:
intl.date_time.pattern_override.date_short set to yyyy-MM-dd
intl.date_time.pattern_override.time_short set to HH:mm
I guess I might need more stuff, but at least for now I don’t see a weird date when I am answering emails.
P.D: Talking about weird things I like to configure… My keyboards are ANSI US QWERTY. But the layout I use is English (intl., with AltGr dead keys). So I can type Spanish letters using the right alt and a key (e.g: AltGr + n gives me ñ).
Last week, as I was writing my trip report about the Google Summer of Code Mentor Summit, I found myself going on a tangent about the program in our community, so I decided to split the content off into a couple of posts. In this post, I want to elaborate a bit on our goal with the program and how intern selection helps us with that.
I have long been saying that GSoC is not a “pay-for-code” program for GNOME. It is an opportunity to bring new contributors to our community, improve our projects, and sustain our development model.
Mentoring is hard and time consuming. GNOME Developers heroically dedicate hours of their weeks to helping new people learn how to contribute.
Our goal with GSoC is to attract contributors that want to become GNOME Developers. We want contributors that will spend time helping others learn and keep the torch going.
Merge-requests are very important, but so are the abilities to articulate ideas, hold healthy discussions, and build consensus among other contributors.
For years, the project proposal was the main deciding factor for a contributor to get an internship with GNOME. That isn’t working anymore, especially in an era of AI-generated proposals. We need to up our game and dig deeper to find the right contributors.
This might even mean asking for fewer internship slots. I believe that if we select a smaller group of people with the right motivations, we can give them the focused attention and support to continue their involvement long after the internship is completed.
My suggestion for improving the intern selection process is to focus on three factors:
History of Contributions in gitlab.gnome.org: applicants should solve a few ~Newcomers issues, report bugs, and/or participate in discussions. This gives us an idea of how they perform in the contributing process as a whole.
Project Proposal: a document describing the project’s goals and detailing how the contributors plans to tackle the project. Containing some reasonable time estimates.
An interview: a 10 or 15 minutes call where admins and mentors can ask applicants a few questions about their Project Proposal and their History of Contributions.
The final decision to select an intern should be a consideration of how the applicant performed across these aspects.
Contributor selection is super important, and we must continue improving our process. This is about investing in the long-term health and sustainability of our project by finding and nurturing its future developers.
If you want to find more about GSoC with GNOME, visit gsoc.gnome.org



 You attended the F43 Virtual Release Party!
You attended the F43 Virtual Release Party!



 You dropped by the Fedora booth at FOSDEM '26
You dropped by the Fedora booth at FOSDEM '26

 to manage an issue tracker. No matter how you choose to do it, someone will be mad about it. In general projects should handle issues however they want, so long as the expectations are clearly managed. If everyone involved knows what to expect (ideally with documentation), that’s all that matters.
to manage an issue tracker. No matter how you choose to do it, someone will be mad about it. In general projects should handle issues however they want, so long as the expectations are clearly managed. If everyone involved knows what to expect (ideally with documentation), that’s all that matters.




 ”
”



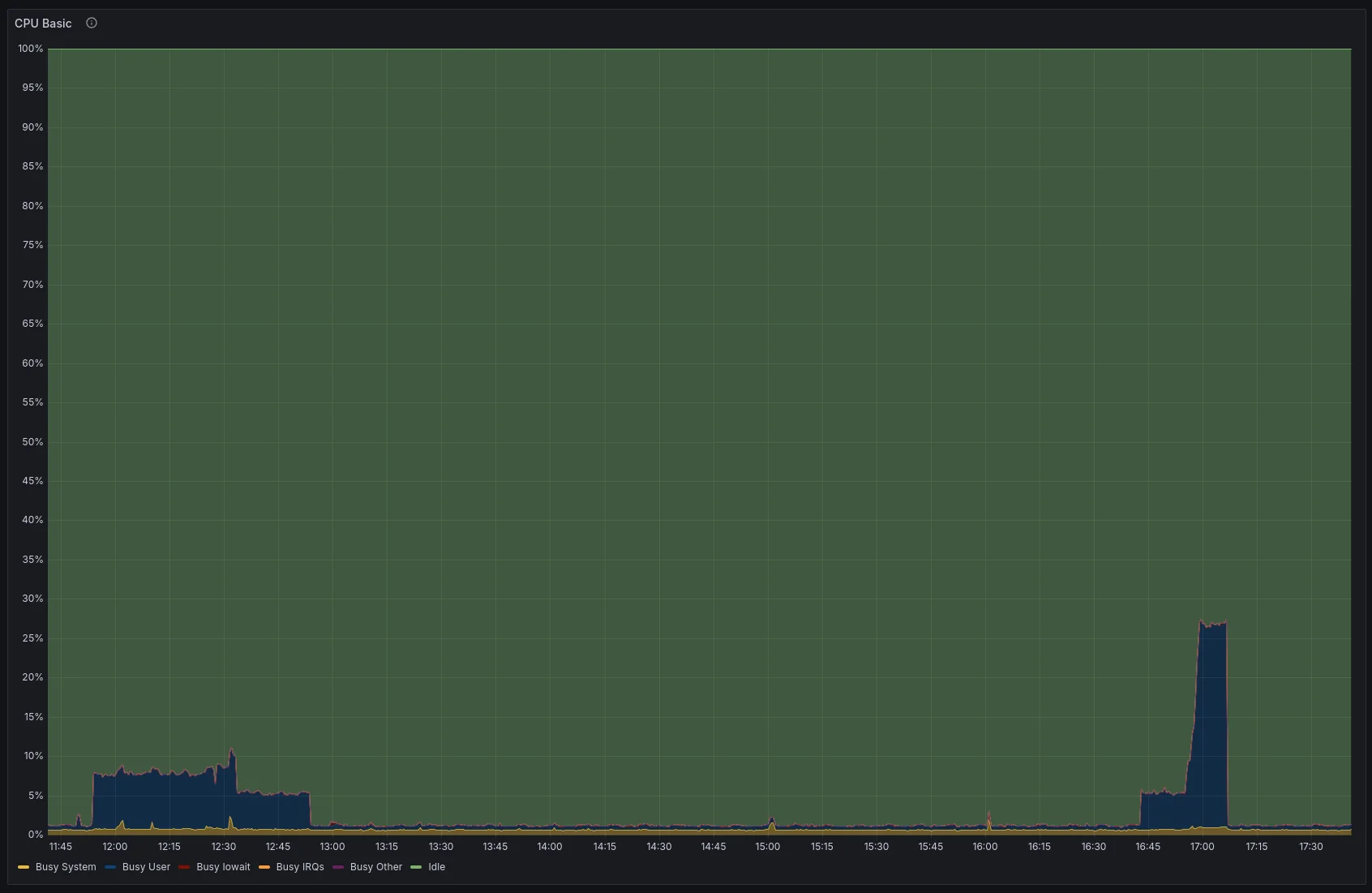


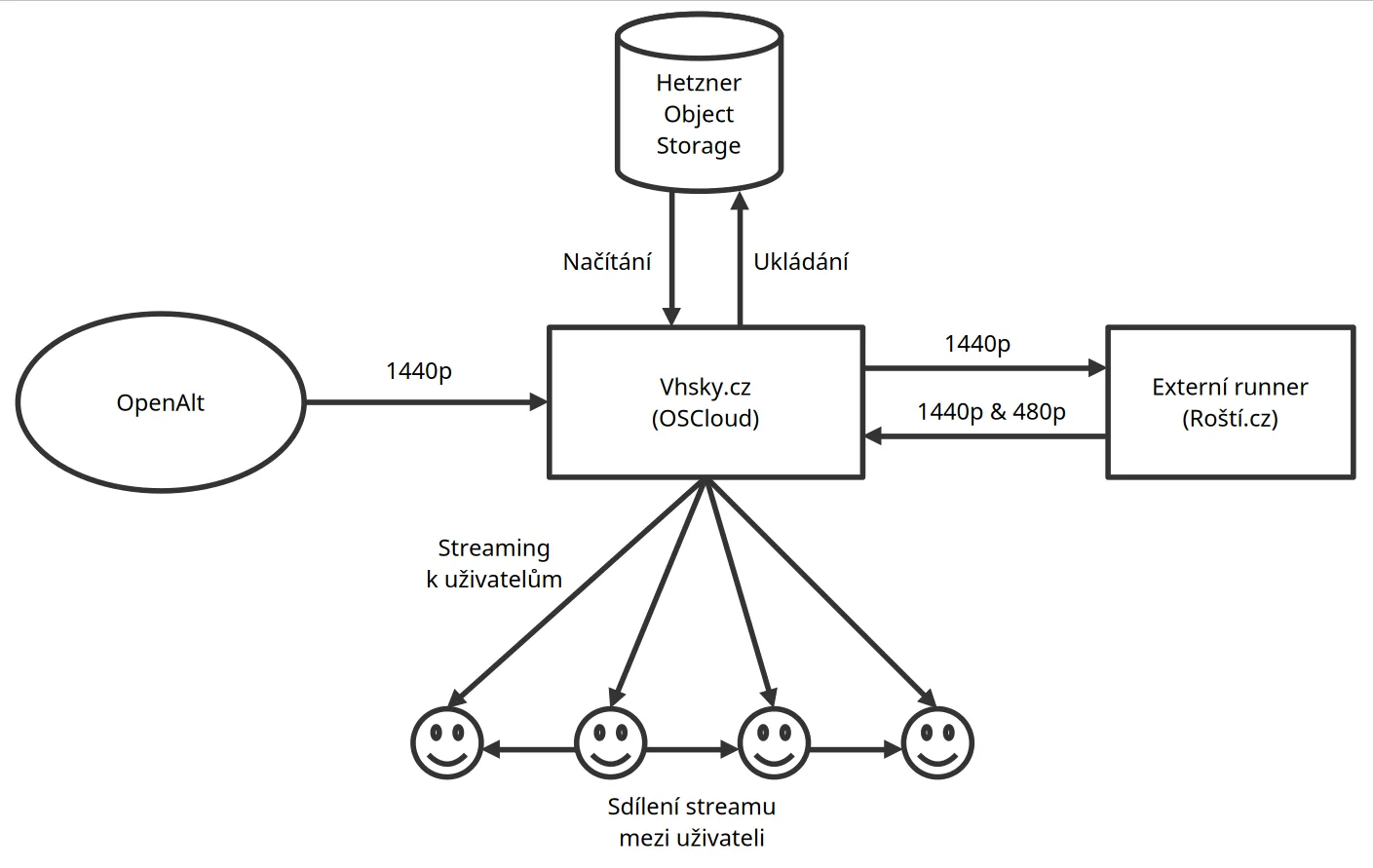




























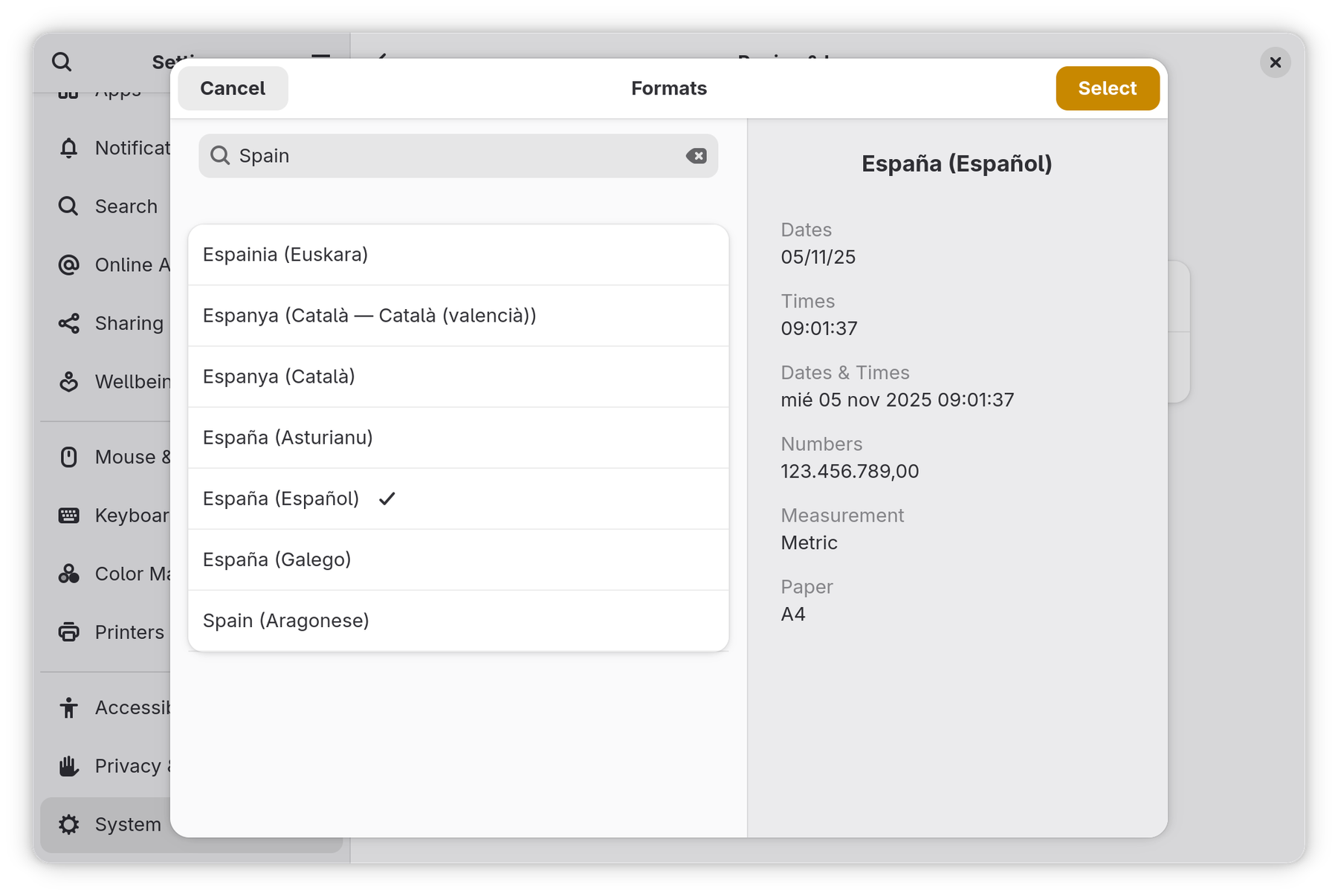
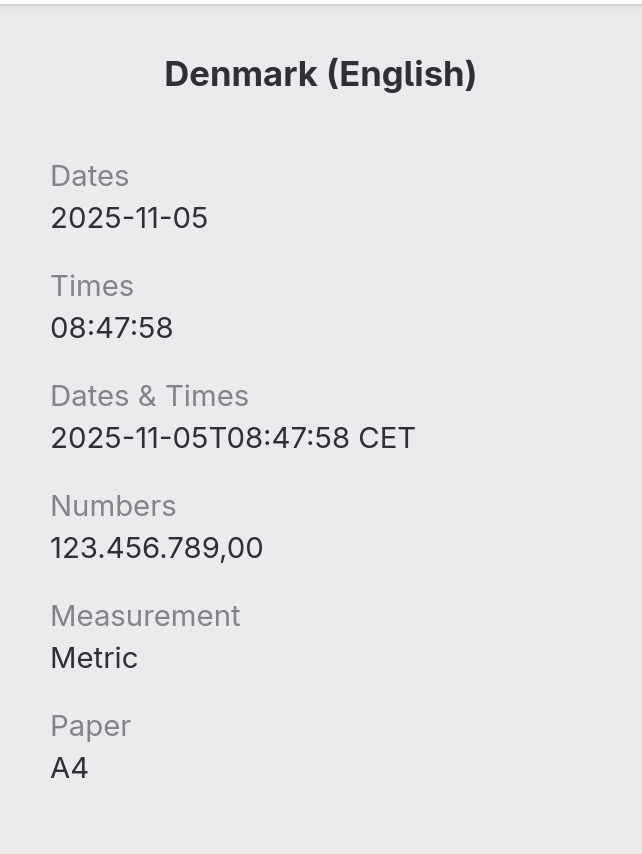

comments? additions? reactions?
As always, comment on mastodon: https://fosstodon.org/@nirik/115595437083693195